Sentiment analysis on Ellen’s DeGeneres tweets using TextBlob


Let’s take the example of any product company. The success of the company or its product directly depends on its customer. If the customer likes their product, then the product is a success. If not, then the company certainly needs to improve its product by making changes to it.
How does the company know whether their product is successful or not?
For that, the company needs to analyze their customers and one of the attributes is to analyze the customer’s sentiment.
What is Sentiment Analysis?

It is a process of computationally identifying and categorizing opinions from a piece of text and check whether the writer’s attitude towards a particular topic or the product is positive, negative or neutral.
Sentiment analysis is a popular topic of great interest and development, and it has a lot of practical applications. There are many publicly and privately available data sources over the internet which is constantly growing. A large number of texts expressing opinions are available in social media, blogs, forums etc.
Using sentiment analysis, unstructured data could be automatically transformed into structured data of public opinions about products, services, brands, politics or any topic that people can express opinions about it. Identifying sentiments from the text data can be very useful for tasks like marketing analysis, public relations, product reviews, net promoter scoring, product feedback, and customer service etc.
Input:
A corpus. It is a collection of text documents and we want to get sentiment from these texts. For example, if the text has great then we want that to be flagged as positive but if we have a word or phrase that’s not great in there, then we want to that to be flagged as negative so we want to keep all of our original text in the original order so that we can capture sentiments.
TextBlob:
TextBlob is a Python library that is built on top of nltk. It’s easier to use and provides some additional functionality, such as rules-based sentiment scores. TextBlob finds all of the words and phrases that it can assign a polarity and subjectivity to, and averages all of them together. More information can be found in the documentation.
Output:
For each word, we will get a sentiment score (how positive/negative are they) and a subjectivity score (how opinionated are they)
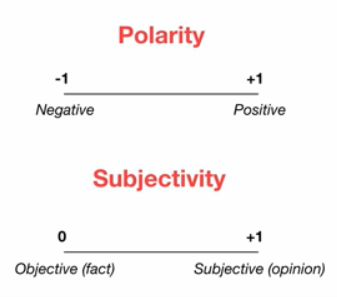
- Polarity: How positive or negative a word is. -1 is very negative. +1 is very positive.
- Subjectivity: How subjective, or opinionated a word is. 0 in fact. +1 is very much opinion.
In this blog post, we will extract twitter data using tweepy. Do sentiment analysis of extracted tweets using TextBlob library in Python
Importing necessary libraries
import pandas as pd import numpy as np import tweepy # to use Twitter’s API import textblob as TextBlob # for doing sentimental analysis import re # regex for cleaning the tweets
Creating a Twitter App
In order to extract tweets, we need to access to our Twitter account and create an app. We can get the credentials from here
# Twitter Api Credentialsconsumer_key = “Your consmer key” consumer_secret = “Your consumer secret key” access_token = “Your acess token” access_token_secret = “Your access token secret”
Creating a function to access Twitter API
def twitter(): # Creating the authentication object auth = tweepy.OAuthHandler(consumer_key, consumer_secret) # Setting your access token and secret auth.set_access_token(access_token, access_token_secret) # Creating the API object while passing in auth information api = tweepy.API(auth, wait_on_rate_limit = True) return api
Getting Tweets
We can create a ‘tw’ object by using the above twitter function. Let’s analyze Ellen DeGeneres tweets. A count is a number of tweets. Printing the last ten tweets. More information on Tweepy can be found in the documentation.
# Creating tw object tw = twitter()# Extracting Ellen DeGeneres tweetssearch = tw.user_timeline(screen_name="TheEllenShow", count = 200, lang ="en")# Printing last 10 tweetsprint("10 recent tweets:\n") for tweets in search[:10]: print(tweets.text + '\n')

Creating DataFrame
Extracted the tweets, now converting into a data frame
# Converting into dataframe (Column name Tweets)df = pd.DataFrame([tweets.text for tweets in search], columns=[‘Tweets’]) df.head(10)
Before doing sentiment analysis, let’s clean the tweets using a regex function. Created a small function called clean.
# Cleaning the tweets # Creating a function called clean. removing hyperlink, #, RT, @mentionsdef clean(x): x = re.sub(r’^RT[\s]+’, ‘’, x) x = re.sub(r’https?:\/\/.*[\r\n]*’, ‘’, x) x = re.sub(r’#’, ‘’, x) x = re.sub(r’@[A-Za-z0–9]+’, ‘’, x) return xdf[‘Tweets’] = df[‘Tweets’].apply(clean)

Sentiment Analysis
Let’s do sentiment analysis using TextBlob. Finding both polarity and subjectivity. Calculating polarity and subjectivity.
polarity = lambda x: TextBlob(x).sentiment.polarity subjectivity = lambda x: TextBlob(x).sentiment.subjectivitydf[‘polarity’] = df[‘Tweets’].apply(polarity) df[‘subjectivity’] = df[‘Tweets’].apply(subjectivity)
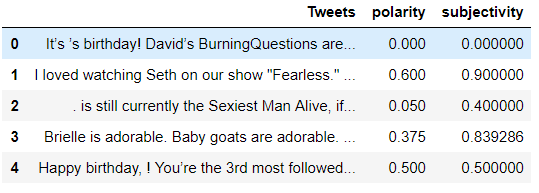
Visualization
# Let’s plot the results import matplotlib.pyplot as plt %matplotlib inlineplt.rcParams[‘figure.figsize’] = [10, 8]for index, Tweets in enumerate(df.index): x = df.polarity.loc[Tweets] y = df.subjectivity.loc[Tweets] plt.scatter(x, y, color=’Red’) plt.title(‘Sentiment Analysis’, fontsize = 20) plt.xlabel(‘← Negative — — — — — — Positive →’, fontsize=15) plt.ylabel(‘← Facts — — — — — — — Opinions →’, fontsize=15)plt.show()

We can see more positives than negatives. Let’s calculate how many tweets are positive, negative, and neutral.
# Creating function for calculating positive, negative and neutral # More than 1 --> Positive, equal to 0 --> neutral and less than 0 --> Negativedef ratio(x): if x > 0: return 1 elif x == 0: return 0 else: return -1df['analysis'] = df['polarity'].apply(ratio)
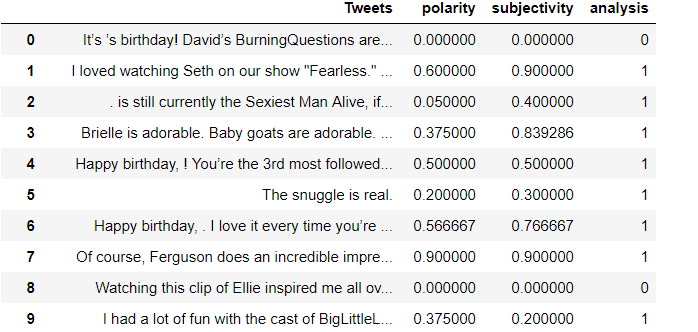
df['analysis'].value_counts()
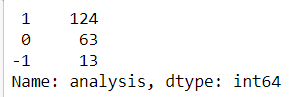
# Plotting df[‘analysis’].value_counts().plot(kind = ‘bar’) plt.show()

Ellen DeGeneres is undoubtedly one of the famous celebrities, people are more positive and enjoying her show.
The above sentiment analysis is a simple one used by TextBlob. We can also do the analysis by searching for any trending or hashtag on Twitter.
Thanks for reading. Keep learning and stay tuned for more!