How I used Clustering to analyze ride-sharing data from Uber


According to Gartner, by 2020, a quarter billion connected vehicles will form a major element of the Internet of Things. Connected vehicles are projected to generate 25GB of data per hour, which can be analyzed to provide real-time monitoring and apps, and will lead to new concepts of mobility and vehicle usage. Ref: Gartner

Uber Technologies Inc is a peer-to-peer ridesharing platform. Uber platform connects the cab drivers who can drive to the customer location. Uber uses machine learning, from calculating pricing to finding the optimal positioning of cars to maximize profits. Used public uber trip dataset to discuss building a real-time example for analysis and monitoring of car GPS data.
The Uber trip dataset, which contains data generated by Uber from New York City. The data is freely available on FiveThirtyEight.

The data from New York City which has five boroughs: Brooklyn, Queens, Manhattan, Bronx, and Staten Island. Applied K-means Clustering on this dataset to understand the trips taken on Uber and identify different boroughs within New York.
Clustering is the process of dividing the datasets into groups, consisting of similar data-points”. Clustering is a type of unsupervised machine learning, which is used when you have unlabeled data.
Here, we have applied a K-Means clustering algorithm whose main goal is to group similar elements or data points into a cluster. “K” in K-means represents the number of clusters. You can check here for working principle of K-Means algorithm.
This blog discussed the use case of how the clustering algorithm used in Uber ridesharing dataset. Total 6 clusters identified and not discussed the validation of clusters in this blog. Mostly focused on interpretation and understanding the concepts in the real world.
Importing necessary libraries

Uber pickups data were available in FiveThirtyEight from April to September 2014. Here, I have used August 2014 dataset for the explanation.
Reading the CSV file
Output
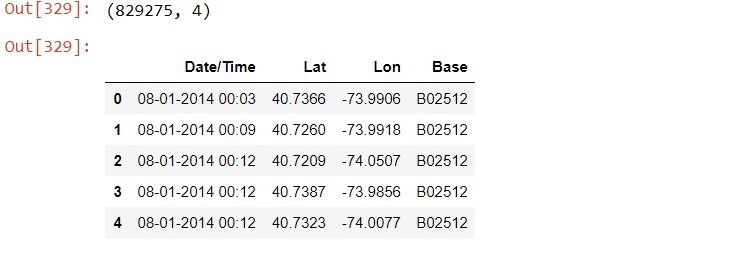
The dataset has 829,275 observations and four columns. It has four attributes,
- Date/Time: The date and time of the Uber pickup.
- Lat(Latitude): The latitude of the Uber pickup
- Lon(Longitude): The longitude of the Uber pickup.
- Base: the TLC base company code affiliated with the Uber pickup.
Selecting features
Here, selecting Latitude and Longitude in a separate data frame called ‘clus’.

Output

We are applying a K-Means clustering. The first step is to find the optimal value for K. This can be found out through Elbow plot as shown below.
Output

Output
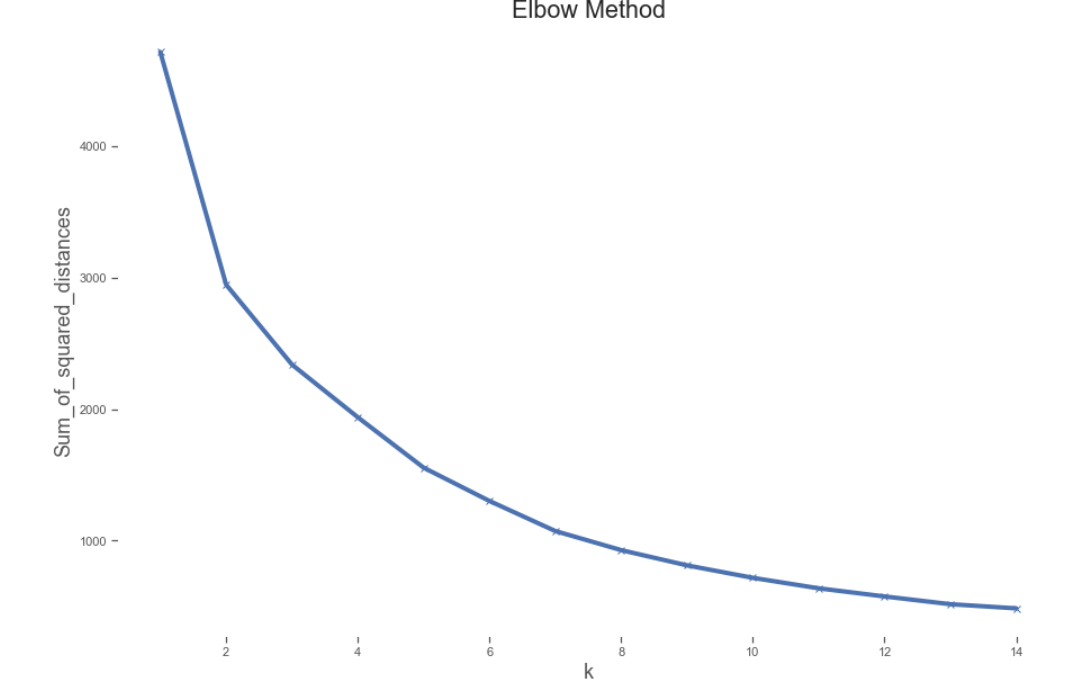
From the above Elbow plot, we can see that the sum of the squared distance of the observations from their closest cluster centroid keeps decreasing with an increase in the number of clusters. We can see that post K=6 there is a significant reduction. We can choose either 6 or 7 clusters. Selected 6 for this dataset.
Performing k-Means Clustering
Assigning a number of cluster in K-Means algorithm

Output

Storing the Cluster Centroids
Storing cluster centroids in a different object called centroids.

Output

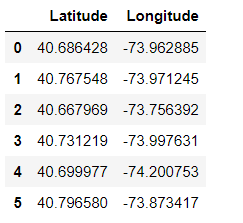
We can see six centroids from the above output. For example, 40.68, -73.96 is the centroid for cluster 1 that is latitude and longitude value for centroid 1. Similarly, we have centroids for other clusters.
Visualizing centroids

Taking latitudes and longitudes from the centroids and converted into two separate data frame. Merged both the data frame and named it as a ‘clocation’ for easy visualization.
Output

Output
We can see all the centroids pertains to each cluster in the above scatterplot. However, this doesn’t show any meaningful information. Let’s plot the same in google map (latitude & longitude) and visualize
Here, we used a folium library for generating the map. Passing the centroids and map the location

Output
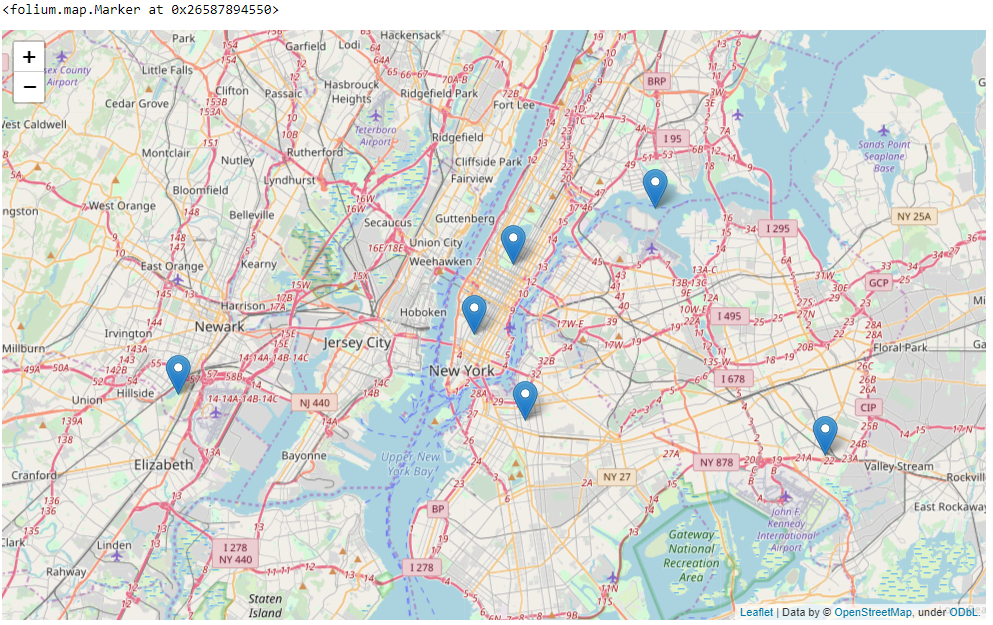
We can see that all the six centroids have been plotted on the map. How these centroids helpful for Uber?
- Uber can use these centroids as their hubs. Whenever Uber received a new ride request, they can check the closeness with each of these centroids. Whichever particular centroid is closer then the Uber can direct the vehicle from that particular location to the customer location.
- Uber has many drivers and providing services to many locations. If Uber knows the hub (particular centroid), and if they are getting a lot of ride request then strategically they can place their driver’s in good location wherein probability of getting a ride request are huge. This will help Uber to serve the customer faster as vehicles are placed closer to the location and also it help to grow their business.
- Uber can make use of these centroids for the optimal placing of their vehicles. They can find which centroid at which part of the day more ride request come in. For example, if Uber get more request from centroid 0 (cluster 1) at 11 AM, but very less request from centroid 3 (cluster 4), then they can redirect the vehicles to cluster 1 from cluster 4 (if more vehicle presence in cluster 4).
- Uber can use these centroids for optimal pricing by analyzing which cluster deals with maximum requests, peak times etc. Suppose, if they don’t have too many vehicles to be sent to a particular location (more demand), then they can do optimal pricing as demand is high and supply is less.
Storing Clusters
Storing the clusters and merging the same into original dataset

Output
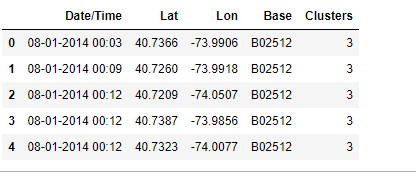
Which cluster receives maximum ride request?
Grouping and visualizing the total number of clusters

Output

Cluster 3 received maximum ride request followed by cluster 1. Cluster 4 received the least request. Uber can place more vehicles in Cluster 3 to meet higher demands.
Checking new location
If Uber gets a new ride request (as getting their new location through longitude and latitude) then pass the latitude and longitude value, then it would predict which cluster from the vehicle should go?

Output
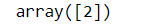
Passing the new request latitude and longitude value (40.65,-73.56). The new request will be assigned to cluster 2 as it’s a distance from the centroid of cluster 2 is minimum as compared to other centroids. The vehicle will come from cluster 2.
Here, we have taken data only for August 2014 which pertains to five-borough. In a real-time, we have more centroids (latitude and longitude) as Uber presence in many countries and giving services for many locations. These centroids will act as a hub for all their ride requests in a defined area.
The above shows how K-Means clustering helps Uber in optimal pricing, the optimal position of cars in order to serve their customer faster and grow their business.
Keep learning and stay tuned for more!